The companion vignette shows that faSTM runs
the same analysis as the stm package. This one
covers what faSTM adds on top of that framework:
multiple content covariates, an estimateEffect() with
weights and clustering, alternative coherence metrics, and a
tidyverse-friendly surface. None of these require leaving the
stm-compatible object; they are extra tools, not a
different model.
We use a second bundled corpus, congress: a balanced
sample of 1,679 U.S. House and Senate floor speeches,
Congresses 100–111 (1987–2011), with metadata party
(Democrat/Republican), chamber (House/Senate), and
congress (the time index). It is built for exactly this
vignette: two categorical covariates that cross, plus a time axis.
library(faSTM)
data(congress)
congress
#> <faSTM_corpus> 1679 documents, 4110 vocabulary terms, 3 metadata columns
table(congress$meta$party, congress$meta$chamber)
#>
#> House Senate
#> Democrat 420 420
#> Republican 419 420We fit one prevalence model (topic prevalence as a function of party and a smooth of time) and reuse it throughout.
Multiple content covariates
stm allows a single content (SAGE) covariate. faSTM
accepts several and crosses them into a saturated
content model: one topic-word distribution per combination of levels.
Here party (2) × chamber (2) gives a 4-group
content model, so we can read how Democrats vs Republicans and
House vs Senate word each topic differently:
fitC <- stm(congress, K = 12,
prevalence = ~ party + s(congress),
content = ~ party + chamber, # crossed -> 4 SAGE groups
verbose = FALSE)
fitC$settings$dim$A # number of content groups
#> [1] 4The fit reports the crossing as it runs, and stm’s SAGE
tooling works unchanged on the result:
sageLabels(fitC, n = 5) # top words per topic, per party×chamber group
labelTopics(fitC, topics = 3)The crossed levels are stored on the fit
(settings$covariates$contentvars,
contenttable) so per-covariate marginals can be recovered
later.
Framing, not agenda
Content covariates are where the interesting partisan signal lives.
Above, estimateEffect will show that Democrats and
Republicans devote similar prevalence to the budget/tax topic,
but they word it very differently. A
~ party content model makes that concrete:
fitParty <- stm(congress, K = 12, prevalence = ~ party + s(congress),
content = ~ party, verbose = FALSE)
sl <- sageLabels(fitParty, n = 10)
tax <- which(apply(sl$marginal, 1, function(w) any(grepl("^tax", w))))[1]
sl$marginal[tax, ] # shared topic vocabulary
#> [1] "tax" "budget" "families" "billion" "health"
#> [6] "government" "pay" "care" "spending" "taxes"
sl$bygroup$Democrat[tax, ] # how Democrats word it
#> [1] "sick" "health" "profits" "care"
#> [5] "reconciliation" "foster" "preexisting" "pregnancy"
#> [9] "children" "denied"
sl$bygroup$Republican[tax, ] # how Republicans word it
#> [1] "taxing" "harbor" "blame" "taxed" "error" "green"
#> [7] "criticize" "internet" "computers" "extra"The shared vocabulary is fiscal (tax, budget, spending), but Democrats reach for health, care, children, preexisting, denied while Republicans reach for taxing, taxed, CBO, authority: same topic, opposite framing. This is the distinction prevalence covariates can’t capture and content (SAGE) covariates can.
estimateEffect(): cluster-robust SEs and weights
faSTM keeps stm’s method-of-composition uncertainty
(re-drawing topic proportions per simulation) and adds design features
grouped data usually needs.
Cluster-robust standard errors. Speeches within a
Congress are not independent, so we cluster by congress.
faSTM swaps the classical vcov for a sandwich estimator with
stm’s finite-sample correction:
eff <- estimateEffect(1:12 ~ party + s(congress), fit,
metadata = congress$meta,
cluster = congress$meta$congress, nsims = 25)
summary(eff, topics = 3)
#> faSTM estimateEffect (Global uncertainty, 25 draws)
#>
#> topic3:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.0951 0.0047 20.0328 0.0000
#> partyRepublican 0.0028 0.0070 0.3964 0.6919
#> s(congress)1 -0.1217 0.0333 -3.6538 0.0003
#> s(congress)2 0.0822 0.0211 3.8978 0.0001
#> s(congress)3 -0.0332 0.0144 -2.3109 0.0210
#> s(congress)4 0.0314 0.0164 1.9192 0.0551
#> s(congress)5 -0.0156 0.0139 -1.1232 0.2615
#> s(congress)6 0.0193 0.0111 1.7326 0.0834
#> s(congress)7 0.0100 0.0127 0.7858 0.4321
#> s(congress)8 0.0302 0.0206 1.4685 0.1422
#> s(congress)9 0.0139 0.0237 0.5847 0.5588
#> s(congress)10 -0.0176 0.0054 -3.2775 0.0011
#> R-squared: 0.005 | F(11,1667): 0.81summary() also takes p.adjust.method
(e.g. "BH") to correct across topics, and reports
per-equation R² and F diagnostics. Survey weights enter
the same way via weights = (weighted least squares per
draw).
Random effects in prevalence
Prevalence formulas may include lme4-style random-effect
terms; faSTM fits a mixed model per posterior draw and pools with
Rubin’s rules. Natural here if you treat Congresses as exchangeable
groups:
eff_re <- estimateEffect(1:12 ~ party + (1 | congress), fit,
metadata = congress$meta, nsims = 25)
summary(eff_re, topics = 3) # fixed effects + pooled variance componentsAverage marginal effects
Coefficients on splines and factors are hard to read.
ame() reports the average marginal effect:
the mean change in topic proportion for a Republican-vs-Democrat shift,
averaged over the sample:
Topic prevalence over time
Because prevalence includes s(congress), we can trace a
topic’s share across the 1987–2011 window:
plot(eff, "congress", method = "continuous", topics = 3,
model = fit, xlab = "Congress (100 = 1987 ... 111 = 2009)")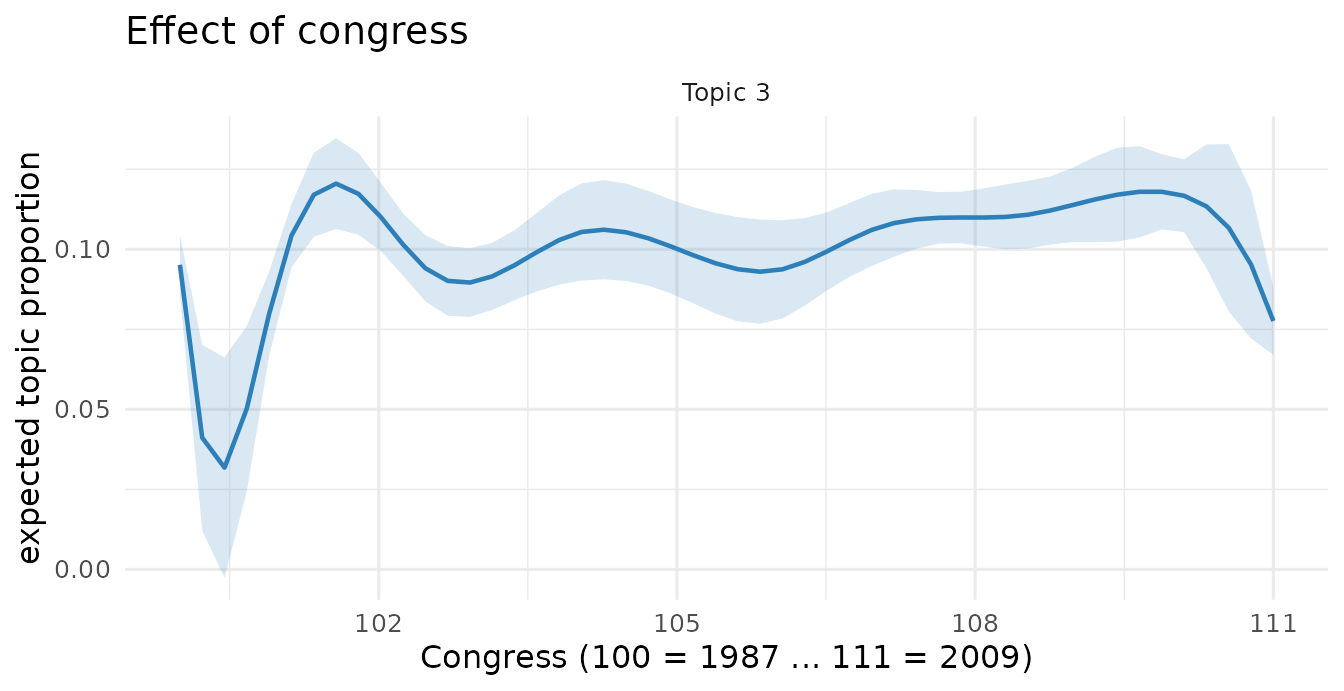
Coherence: NPMI and C_V
Alongside Mimno’s semantic coherence, faSTM offers two more coherence metrics common in the topic-model literature: NPMI and C_V:
data.frame(
topic = 1:5,
mimno = round(coherence(fit, measure = "mimno", M = 10)[1:5], 2),
npmi = round(coherence(fit, measure = "npmi", M = 10)[1:5], 3),
c_v = round(coherence(fit, measure = "c_v", M = 10)[1:5], 3)
)
#> topic mimno npmi c_v
#> 1 1 -69.34 0.101 0.553
#> 2 2 -73.12 0.142 0.634
#> 3 3 -51.61 0.135 0.640
#> 4 4 -68.07 0.140 0.642
#> 5 5 -89.67 0.153 0.663search_k() can select K by any of these, and
parallelizes across K:
A tidyverse-friendly surface
faSTM ships broom generics, so model output flows
straight into dplyr/ggplot2.
# tidy the topic-word matrix (also matrix = "frex" or "gamma")
head(tidy(fit, matrix = "beta"), 4)
#> topic term beta
#> 1 1 words 5.127769e-04
#> 2 1 daniel 5.698705e-13
#> 3 1 served 3.525644e-04
#> 4 1 armed 2.465336e-12
# one-row model summary
glance(fit)
#> k docs terms content_groups iterations converged
#> 1 12 1679 4110 1 70 TRUE
# tidy an estimated effect into a coefficient table
head(tidy(eff), 4)
#> topic term estimate std.error statistic p.value
#> 1 topic1 (Intercept) 0.07235789 0.004353876 16.619190 1.649890e-57
#> 2 topic1 partyRepublican 0.00550665 0.005370920 1.025271 3.053840e-01
#> 3 topic1 s(congress)1 -0.06616952 0.025091558 -2.637123 8.438957e-03
#> 4 topic1 s(congress)2 0.06182077 0.018241878 3.388948 7.179648e-04predict() infers topic proportions for new documents
against the fitted model:
predict(fit, newdata = held_out_corpus) # a faSTM_corpus / dfm of new docs