We aren't all happy at the same time
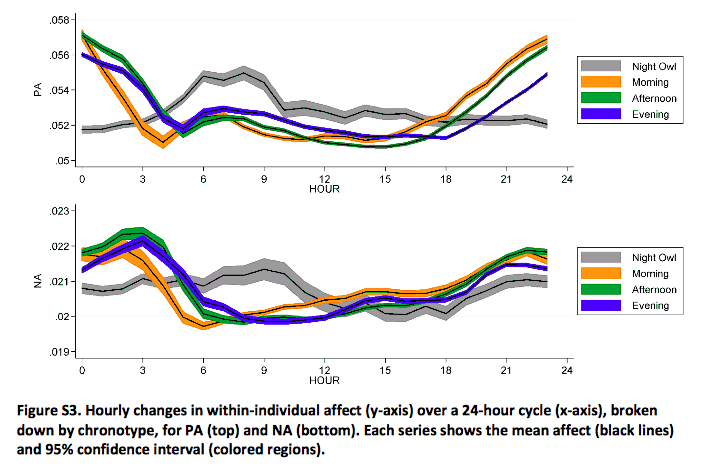
A list based sentiment analysis by Scott Golder and Michael Macy
Winning makes us happy.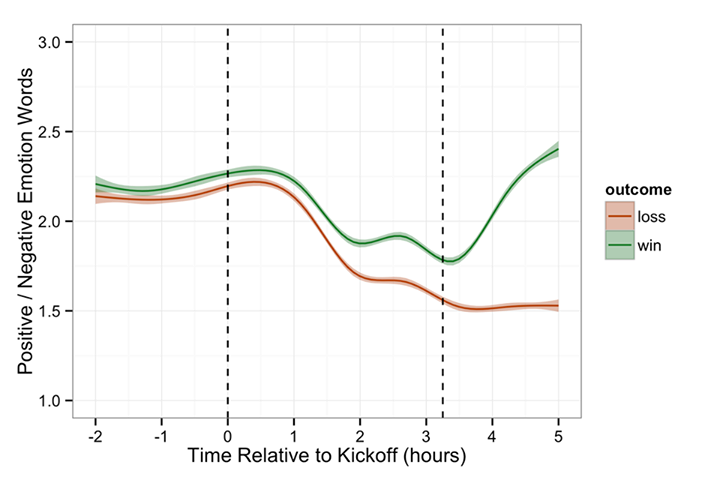
by Sean J. Taylor (@seanjtaylor)
Data types
Strings
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
Open a note book and copy this text over.
Then press shift-enter or select Cell-Run from the pull down menu to run it.
What's in there?
In a new cell, type tweet and then run the cell
tweet
We can also print out the contents.
print tweet
Python doesn't care if you use ', ", or even ''' for your strings.
tweet = "We have some delightful new food in the cafeteria. Awesome!!!"
tweet
Will this work?
tweet = Does anyone call New Haven "NeHa"?
Guess? Try it!
tweet = Does anyone call New Haven "NeHa"?
tweet = '''Does anyone call New Haven "NeHa"?'''
print tweet
tweet = 'Does anyone call New Haven "NeHa"?'
print tweet
Lists - another way to store data
['everything','in','brackets','separated','by','commas.']
Think of these like variables.
positive_words = ['awesome', 'good', 'nice', 'super', 'fun']
print positive_words
We can add things to the list with append.
positive_words.append('delightful')
print positive_words
Note that we didn't write postive_words = positive_words.append('delightful').
.append() modifies the content of the list.
positive_words.append(like)
new_word_to_add = 'like'
positive_words.append(new_word_to_add)
print positive_words
Your turn.
Make a list callled negative_words that includes awful, lame, horrible and bad. print out the contents.
negative_words = ['awful','lame','horrible','bad']
print negative_words
Combining lists
emotional_words = negative_words + positive_words
print emotional_words
Strings can be split to create lists. I do this a lot.
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
words = tweet.split()
print words
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
print tweet.split('.')
Unlike .append(), .split() doesn't alter the string strings. Strings are immutable.
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
print tweet.split()
print tweet
So when you modify a string, make sure you store the results somewhere.
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
words = tweet.split()
print words
Most of the fun math is in numpy but we can count the length of objects.
print words
print len(words)
How long is tweet?
print tweet
len(tweet)
With functions like len(), Python counts the number of items in list and the number of characters in a string.
There's a couple of more data types that you might need:
#tuple
row = (1,3,'fish')
print row
#sets
set([3,4,5,5])
#Dictionary
article_1 = {'title': 'Cat in the Hat', 'author': 'Dr. Seuss', 'Year': 1957}
#And a list of dictionaries is awfully close to a JSON.
article_2 = {'title': 'Go Do Go!', 'author': 'PD Eastman', 'Year': 1961}
articles = [article_1, article_2]
articles
Loops
Was any of our sentence words in the postive word list?
for word in words:
print word
tweet = 'We have some delightful new food in the cafeteria. Awesome!!!'
words = tweet.split()
for word in words :
print word
Note the colon at the end of the first line. Python will expect the next line to be indented.
We can also add conditionals, like if and else or elif.
for word in words:
if word in positive_words:
print word
Your turn. Take the following tweet and print out a plus sign for each positive word:
tweet_2 = "Food is lame today. I don't like it at all."
Don't peak.
tweet_2 = "Food is lame today. I don't like it at all."
words_2 = tweet_2.split()
for word in words_2:
if word in positive_words:
print '+'
tweet_2 = "Food is lame today. I don't like it at all."
tweet_2 = tweet_2.replace("n't"," not")
tweet_2 = tweet_2.replace("not "," not_")
print tweet_2
words_2 = tweet_2.split()
for word in words_2:
if word in positive_words:
print '+'
if word in negative_words:
print '-'
Like lists, we can combine strings with a +.
for word in words:
if word in positive_words:
print word + ' is a positive word.'
Why doesn't this work?
print 3 + ' is a number.'
print ['puppies','dogs'] + 'are pets.'
print '3' + ' is a number.'
print str(3) + ' is a number.'
print '%s is a number.' % 3
for some_number in [1,2,4,9]:
sentence = str(some_number) + ' is a number.'
print sentence
Text cleaning
Or why Awesome!!! wasn't a positive word
print tweet.lower()
But we can't do it with a list of things.
print words.lower()
So you'll either need clean the whole sentence, each word, or both.
for word in words:
word_lower = word.lower()
if word_lower in positive_words:
print word_lower + ' is a positive word.'
Updating our loop, we still don’t find awesome!!! yet.
Why?
print 'awesome!!!'.strip('!')
Getting rid of `'!"#
from string import punctuation
punctuation
'awesome!!!!'.strip(punctuation)
'awesome?!?!'.strip(punctuation)
'awesome!!!! party'.strip(punctuation)
print 'awesome!!! party'
print 'awesome!!! party'.replace('!','')
word = 'awesome!!!'
word_processed = word.strip('!')
word_processed = word_processed.lower()
print word_processed
word = 'awesome!!!'
word_processed = word.strip('!').lower()
print word_processed
for word in words:
word_processed = word.lower()
word_processed = word_processed.strip(punctuation)
if word_processed in positive_words:
print word + ' is a positive word'
It worked!!!
But what we really care about is the count of words.
postive_counter = 0
for word in words:
word_processed = word.lower()
word_processed = word_processed.strip(punctuation)
if word_processed in positive_words:
postive_counter = postive_counter + 1
print postive_counter
Let's do this for real.
- Get a real list of affect words.
- Get a real list of tweets.
- Output the results to a csv file for additional analysis.
LIWC is what all the cool kids use, but there list is copyrighted. So we'll use lists of positive and negative words from:
Theresa Wilson, Janyce Wiebe and Paul Hoffmann (2005). "Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis." Proceedings of HLT/EMNLP 2005, Vancouver, Canada.
negative_file = open(r'/Users/nealcaren/Downloads/nealcaren-workshop_2014-4b4f226-3/notebooks/negative.txt', 'r').read()
The basic way to open and read a text file.
r tells the operating system you want permission to read it..read() tells Python to import all the text
Let's take a look at negative_file by slicing it up.
negative_file[:50]
\n is an End of Line character
[:50] took the first 50 characters
negative_list = negative_file.split('\n')
negative_list[:5]
negative_list = negative_file.splitlines()
negative_list[:5]
Python starts at 0
print negative_list[0]
print negative_list[0:1]
print negative_list[-5:]
Let's do it again for the postive words
postive_file = open('positive.txt', 'r').read()
postive_list = postive_file.splitlines()
print postive_list[-2:]
Quiz: How many words are in the two lists combined?
print len(postive_list) + len(negative_list)
A while back, I use the Twitter API to get some Tweets, or status updates, that mentioned President Obama.
obama_tweets = open('obama_tweets.txt', 'r').read()
obama_tweets = obama_tweets.splitlines()
Avoid copy and paste text in file! Make a function!
def open_list(filename):
list_file = open(filename, 'r').read()
list_file = list_file.splitlines()
return list_file
obama_tweets = open_list('obama_tweets.txt')
More slicing
obama_tweets[:5]
Some from the middle?
print obama_tweets[52:55]
That's ugly.
for tweet in obama_tweets[52:55]:
print tweet
Let's get going!!!
#loop, but don't go through everything yet
for tweet in obama_tweets[:5]:
print tweet
positive_counter = 0
#Lower case everything
tweet_processed = tweet.lower()
#split by ' ' into a list of words
words = tweet_processed.split()
#Loop through each word in the tweet
for word in words:
clean_word = word.strip(punctuation)
if clean_word in postive_list:
print clean_word
positive_counter = positive_counter+1
print positive_counter,len(words)
Your turn. Add a negative_counter!
#loop, but don't go through everything yet
for tweet in obama_tweets[:5]:
positive_counter = 0
negative_counter = 0
#Lower case everything
tweet_processed = tweet.lower()
#split by ' ' into a list of words
words = tweet_processed.split()
#Loop through each word in the tweet
for word in words:
clean_word = word.strip(punctuation)
if clean_word in postive_list:
positive_counter = positive_counter + 1
if clean_word in negative_list:
negative_counter = negative_counter + 1
print positive_counter, negative_counter, len(words)
Now let's get this out of Python
import csv
csv_file = open('tweet_sentiment.csv','w')
csv_writer = csv.writer( csv_file )
#loop, but don't go through everything yet
for tweet in obama_tweets[:5]:
positive_counter = 0
negative_counter = 0
#Lower case everything
tweet_processed = tweet.lower()
#split by ' ' into a list of words
words = tweet_processed.split()
#Loop through each word in the tweet
for word in words:
clean_word = word.strip(punctuation)
if clean_word in postive_list:
positive_counter = positive_counter + 1
elif clean_word in negative_list:
negative_counter = negative_counter + 1
csv_writer.writerow( [positive_counter, negative_counter, len(words)] )
csv_file.close()
Let's look at the results. If !cat doesn't work, try !type which is the Windows equivalent.
!cat tweet_sentiment.csv
Why only 5 rows?
csv_file = open('tweet_sentiment.csv','w')
csv_writer = csv.writer( csv_file )
#loop
for tweet in obama_tweets[:]:
positive_counter = 0
negative_counter = 0
#Lower case everything
tweet_processed = tweet.lower()
#split by ' ' into a list of words
words = tweet_processed.split()
#Loop through each word in the tweet
for word in words:
clean_word = word.strip(punctuation)
if clean_word in postive_list:
positive_counter = positive_counter + 1
if clean_word in negative_list:
negative_counter = negative_counter + 1
csv_writer.writerow( [ positive_counter, negative_counter, len(words)] )
csv_file.close()
The csv file can be read in other programs.

That's not Python
If you wanted to add a header, you could by putting
csv_writer.writerow( [ 'postive', 'negative', 'length'] )
before you start writing the values.
In case your wondering, I would probably make my code a little different
def clean_split(tweet):
''' Take sentence and return cleaned list of words '''
return [word.strip(punctuation) for word in tweet.lower().split()]
#turn the lists into sets so we can do intersections
postive_set = set(postive_list)
negative_set = set(negative_list)
sentiment = []
for tweet in obama_tweets:
words = clean_split(tweet)
postive_counter = len( postive_set.intersection(words) )
negative_counter = len( negative_set.intersection(words) )
sentiment.append ( [ postive_counter , negative_counter, len(words)] )
with open('tweet_sentiment_2.csv','w') as csv_file:
csv_writer = csv.writer( csv_file )
csv_writer.writerows(sentiment)
Some takeaways
- That's most of what you need to know in Python.
- List comprehension
- Functions/Classes
- Start simple.
- Develop a solution for one case
- Scale up (so make sure your 2A is generalizable.)